
本地知识库
一站式文献中枢:直检 · 入库 · 检索 · 推理
InkCop 本地知识库是整个工作流的中枢——从四大文献平台直接检索全文与元数据,到批量导入本地多格式资源,再到 RAG + 知识图谱双引擎检索,所有处理由 LiteraturePrepareAgent 全程接管。数据 100% 本地存储,AI 增强检索能力贯穿科研全流程。
四大文献检索平台 · 应用内直连
PubMed 生物医药 生物医学文献权威库(NIH/NLM)
支持 .nbib 格式标准元数据下载
arXiv 理工 物理 / 数学 / 计算机预印本
高级布尔查询 + 学科分类筛选
OpenAlex 开放获取 2 亿+ 学术论文开放索引
OA / 全文可用筛选 + 引用计数
CORE 聚合 全球最大开放获取论文聚合
一键下载全文 PDF 与摘要
LiteraturePrepareAgent · 大模型接管文献处理
传统知识库系统会用规则切片、用规则提取实体、用规则生成摘要——四五个独立模块串联,每一个模块只看到自己那一段输入,整体精度被"短板效应"拖累。InkCop 反其道而行之:把整个预处理流水线交给一个大模型 Agent。
语义分片
由大模型识别文档语义边界进行分片,避免规则分片切碎完整论证段落。同一篇内化用更细,节省后续检索的语义损失。
实体关系抽取
识别人物、机构、概念、方法、指标等实体,并提取实体间的指代、对比、因果、依赖等关系,写入图数据库。
图谱概念生成
为文档生成"概念节点"用于跨文档检索,支持后续多跳推理与孤立概念匹配,让知识图谱真正服务于检索。
摘要 / 关键词 / 分类
一次性产出摘要、关键词、主题分类。配合 Citation 元数据形成文档画像,提升后续检索的精准度。
由 LLM 接管的 6 大好处
为什么不再用「规则 + 多模块」的传统流水线?
上下文一次性看全
传统流水线每个环节只看到自己那一段输入;LLM 接管后,分片、抽取、摘要共享同一份完整上下文,理解层次更深。
原子提交,状态一致
通过 base_data_updater / index_data_updater 工具一次性原子提交所有产出,不会出现"分片成功但图谱抽取失败"的中间状态。
统一规则,易于演进
所有处理逻辑都在 Agent 提示词中,研究领域切换或规则升级只需调整一个 Prompt,不必重写多个独立模块。
降级与重试可控
失败任务保留在 signals 表中,应用启动巡检自动重试;超过阈值后由用户手动触发,避免静默丢失。
充分发挥模型能力
随着大模型能力提升,预处理质量自然受益。无需重写代码,仅需切换更强的模型或优化 Prompt。
可独立配置 LLM
LiteraturePreparer 可与对话用的 main_agent 解耦,单独配置成本更低或速度更快的本地模型用于批量处理。
四大平台直检 · 一键入库
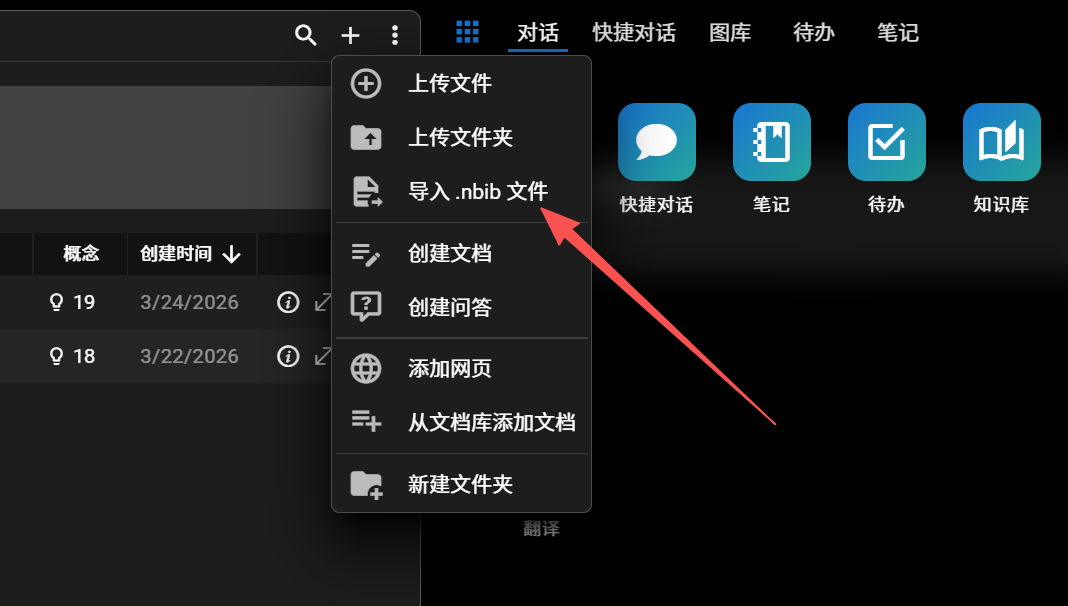
无需在多个网站之间反复切换。在 InkCop 内直接搜索 PubMed / arXiv / OpenAlex / CORE,结果即可批量导入到本地知识库,元数据自动恢复,全文全文索引。
高级查询
布尔表达式 + 字段筛选
勾选 / 全选
多选导入到指定文件夹
批量入库
元数据 + 全文一并保存
PubMed 生物医药 生物医学文献权威库(NIH/NLM)
支持 .nbib 格式标准元数据下载
arXiv 理工 物理 / 数学 / 计算机预印本
高级布尔查询 + 学科分类筛选
OpenAlex 开放获取 2 亿+ 学术论文开放索引
OA / 全文可用筛选 + 引用计数
CORE 聚合 全球最大开放获取论文聚合
一键下载全文 PDF 与摘要
本地批量导入 · 多格式无忧
存量文献再多也不怕。直接拖入文件夹即可递归扫描所有受支持的格式,PDF 通过 MinerU 解析器恢复版式,Word/EPUB/RTF/ODT 由 Pandoc 直转,图像 PNG/JPG 通过 OCR 提取文字。
- 后台异步处理,前端可继续工作
- 应用重启后断点续传,不丢任务
- 入库即触发 LLM 预处理,无需手动干预
- 可选择子文件夹归档,与现有文献结构对齐
PDF 原始排版保留 + AI 元数据恢复
Word .doc / .docx,Pandoc 直转
PowerPoint .ppt / .pptx,幻灯片入库
EPUB 电子书完整章节解析
Markdown 原生格式,零转换损失
RTF / ODT 富文本格式无损导入
图像 / Image PNG / JPG,OCR 文字提取
纯文本 / TXT 日志、笔记、批处理输出
RAG + 知识图谱 双引擎检索
单一向量检索容易"答非所问",单一图谱检索覆盖面太窄。InkCop 让两个引擎并行工作,互相校准,给 AI 提供既"广"且"准"的上下文。
RAG 向量检索
广义语义相似 · 容错性强
- ▸ObjectBox + HNSW 本地索引,毫秒级近邻查询
- ▸支持多模态 embedding(文本 + 图像)
- ▸可选 reranker 模型二次精排
- ▸语义分片粒度由 LLM 接管
知识图谱检索
严谨实体关联 · 多跳推理
- ▸Kuzu 图数据库,原生 Cypher 查询
- ▸支持多跳推理串联跨文献逻辑
- ▸概念节点 + 实体节点双层表示
- ▸每条边都附带 chunk 引用,可逐项验证
检索时双引擎协同: RAG 提供候选 chunk → 图谱按实体关联扩展邻居 chunk → 合并去重 → 可选 LLM 相关性测试 → 返回上下文。整个过程对 LLM 透明,得到"既广又准"的检索结果。
知识图谱可视化 · 让结构看得见
知识图谱不仅服务于 AI 检索,也是研究人员自己的认知工具。基于 AntV G6 的可交互图谱,让你"看见"知识库内的关系网络。
六种布局算法
radial(径向树)、force-cluster(力导聚类)、concentric(同心圆)、antv-dagre(层级)、circular(环形)、grid(网格),系统会根据图密度自动推荐最适合的布局。
概念图 + 文档图双视图
概念图展示跨文献的实体关系网络;文档图展示知识库内文档的相似度与引用关系。一键切换视角。
点击节点递归展开
点击任意节点拉取其邻居子图与现有图合并,渐进式探索图谱深处,无须一次性加载全部数据。
聚焦高亮 + LOD 优化
选中节点时一级邻居高亮、其余降透明度;缩放过低时自动隐藏标签,渲染百万级节点也丝滑流畅。
相关 chunk 与原文跳转
抽屉展示节点关联的 chunk 内容,可直接跳到原文档相应位置。从图谱直达细节,无须切换工具。
关键词检索 + 子图过滤
在工具栏输入关键词或知识库 ID 进行子图过滤;当节点/边超过限制时自动截断并提示用户。
典型使用场景
文献综述
通过概念图发现领域的核心实体网络,定位研究空白;多跳推理串联跨文献的隐含逻辑。
主题探索
面对陌生领域,从一个关键概念出发递归展开邻居节点,快速建立领域认知地图。
关系核查
AI 给出的"X 与 Y 相关"是否真有依据?图谱中的实体边均带 chunk 引用,可逐项验证。
团队知识共享
知识图谱将团队多年文献沉淀可视化,新成员快速 onboarding,避免重复造轮子。
完整能力矩阵
本地知识库为科研全流程提供的核心能力
LLM 接管的文献预处理流水线
LiteraturePrepareAgent 全程接管:文献语义分片、实体关系抽取、图谱数据生成、摘要与关键词全部交给大模型一次调用完成,原子提交,避免传统”多调多管道”造成的上下文丢失与不一致。
四大文献平台直接检索
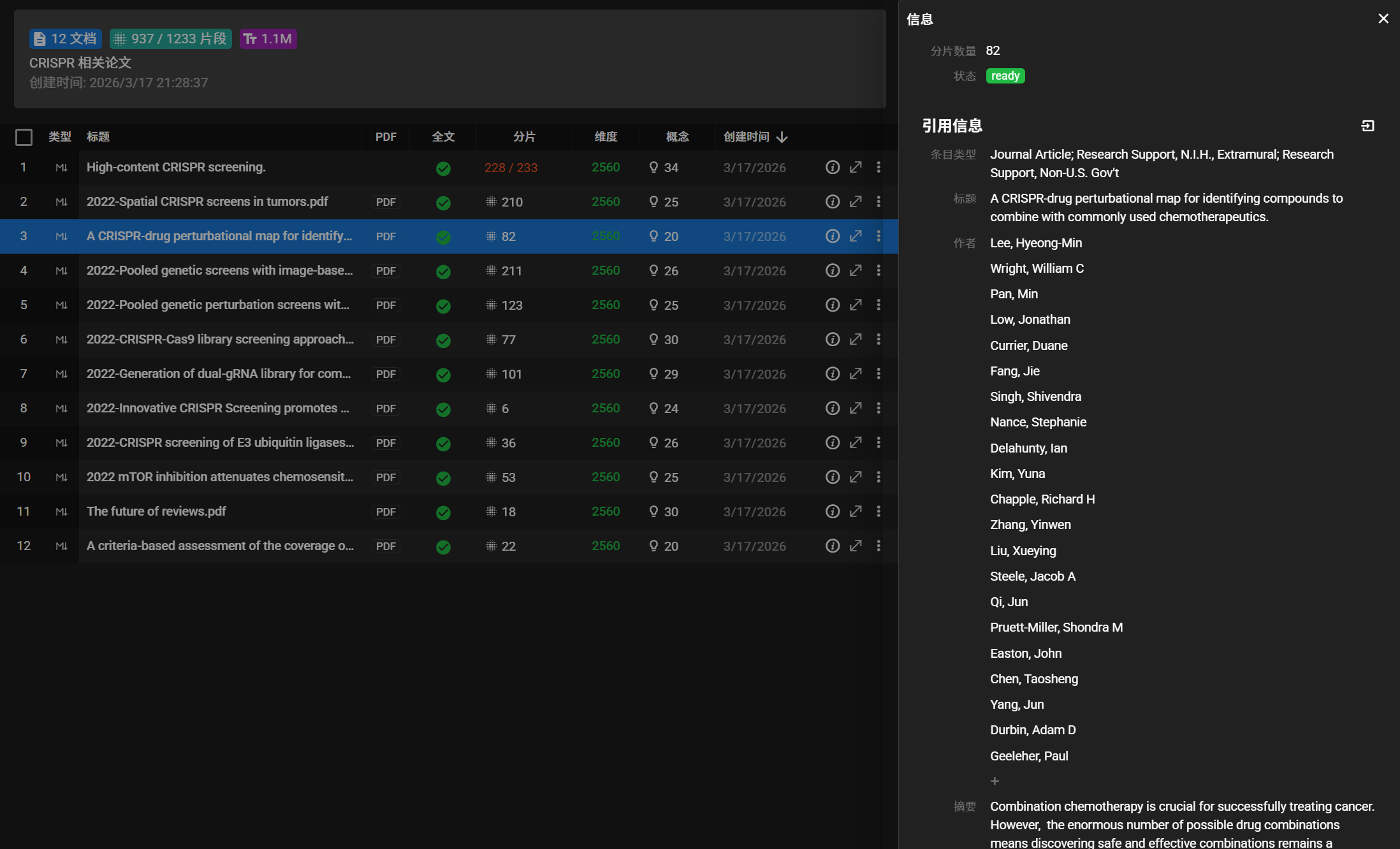
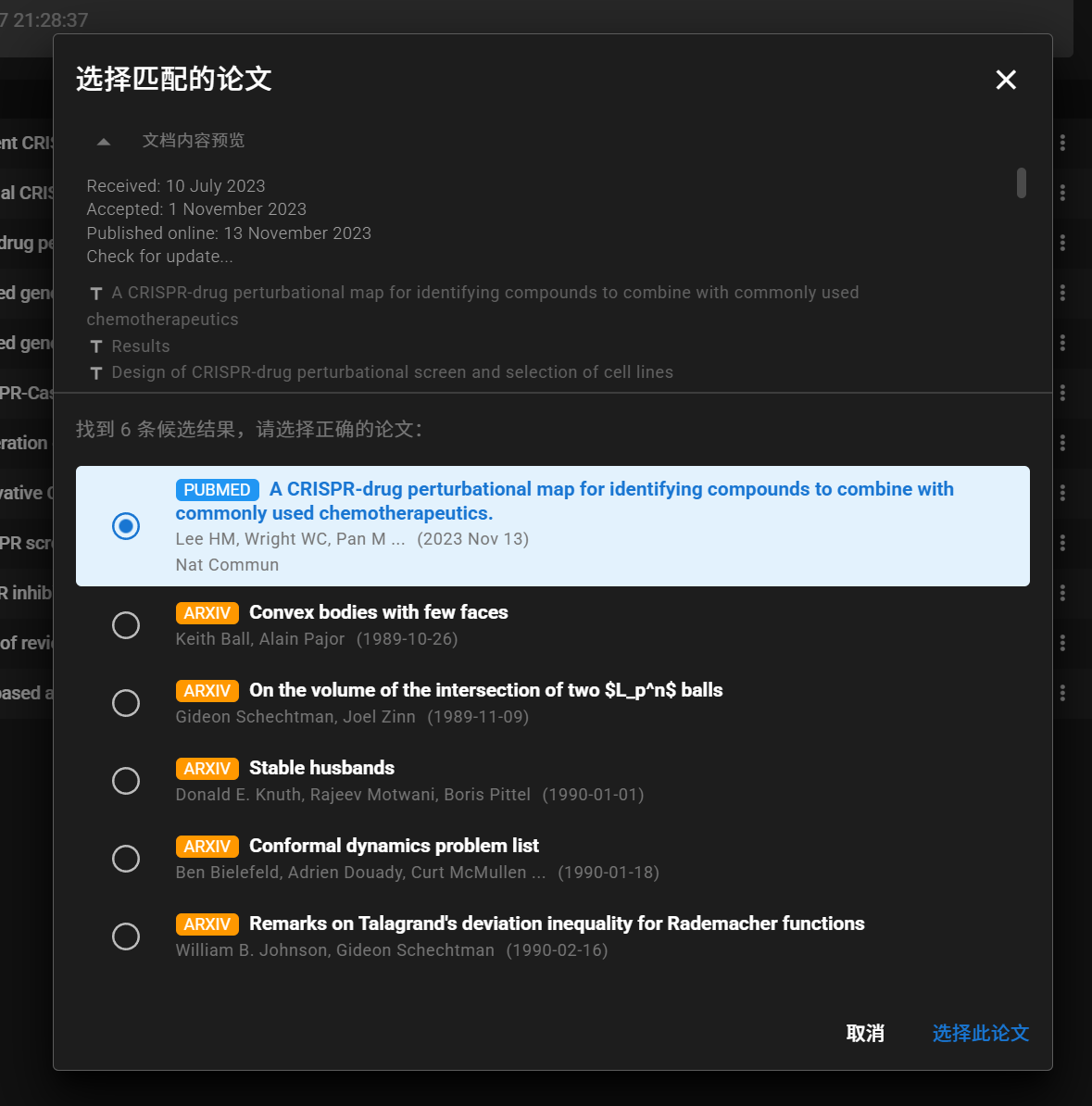
应用内联结 PubMed / arXiv / OpenAlex / CORE 四大文献平台,支持高级布尔查询与多维度筛选,一键批量导入全文 + 完整元数据(标题、作者、期刊、卷期、DOI、PMID等)到本地知识库。
本地批量导入多格式资源
拖入文件夹即可递归导入。全面支持 PDF / Word (.doc/.docx) / PowerPoint (.ppt/.pptx) / EPUB / RTF / ODT / Markdown / 纯文本以及 PNG/JPG 图像(OCR)。跳过「一篇一篇上传」的低效,重启后后台断点续传。
RAG + 知识图谱双引擎检索
传统 RAG 向量检索提供”广义语义相似”,知识图谱提供”严谨实体关联”,二者互补。本地 ObjectBox + HNSW 毫秒级近邻检索,Kuzu 图数据库支持多跳推理,严谨串联不同文献中的隐含脉络。

多模态 RAG 与图表理解
不仅读懂文字,还能识别论文中的图表、曲线图、病理影像等图像资源,转化为可检索的知识单元。支持使用多模态 embedding 模型(如 qwen3-vl-embedding)。

可交互知识图谱可视化
基于 AntV G6 提供概念图 / 文档图双视图,支持径向、力导、同心圆、层级、环形、网格六种布局。点击节点可递归展开邻居、跳转原文、查看相关 chunk。
自动元数据发现与 Citation 存档
拖入任意命名的 PDF,AI 自动恢复文献标题、作者、摘要、期刊名、DOI、PMID 等核心元数据,并以 Zotero 风格的 Citation 结构保存于 metadata 字段。支持 .nbib 文件导入。
文献导读与可视化报告
为入库文献一键生成导读、倒读、图解与 HTML 可视化报告,10 分钟掌握一篇论文核心,告别逐行精读的低效。
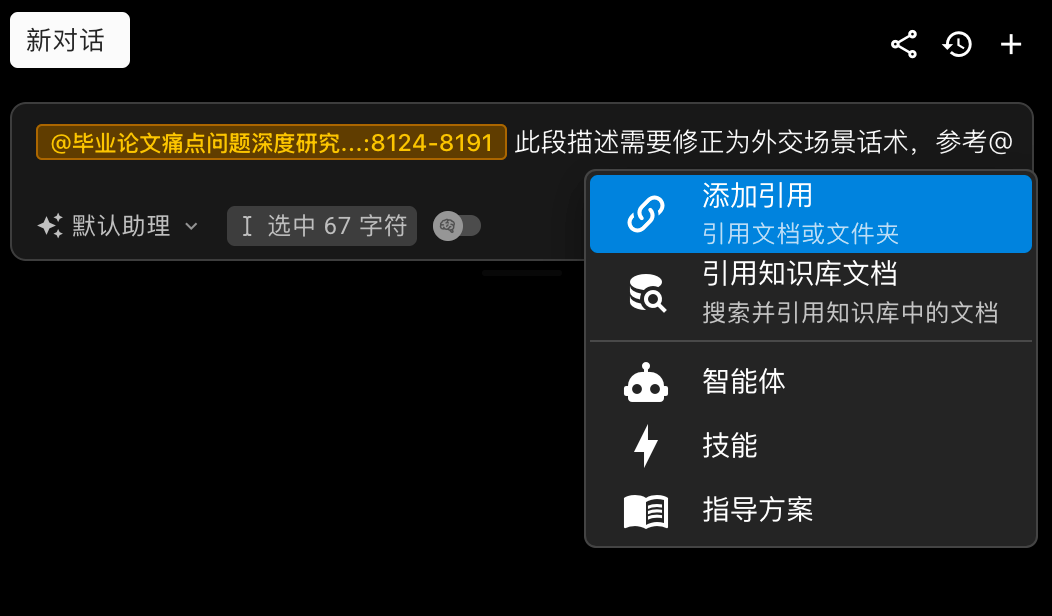
@精准定位与上下文钉选
对话中 @文档、@知识库文献、@文档中具体文字,将上下文“钉住”在客观实体上,AI 回答有据可查,避免含糊幻觉。
本地知识库连通所有解决方案: