
Local Knowledge Base
All-in-One Literature Hub: Search · Import · Retrieve · Reason
InkCop's local knowledge base is the central hub of your workflow — search 4 literature platforms directly, batch import multi-format local resources, then retrieve with dual RAG + Knowledge Graph engines. The LiteraturePrepareAgent owns the full pipeline. 100% local storage with AI-enhanced retrieval throughout your research lifecycle.
4 Literature Platforms · Native Integration
PubMed Biomedical Biomedical authority (NIH/NLM)
Standard .nbib metadata supported
arXiv STEM Physics / Math / CS preprints
Boolean query + subject filters
OpenAlex Open Access 200M+ open scholarly index
OA / fulltext filter + citation counts
CORE Aggregator World's largest OA paper aggregator
One-click full-text PDF & abstract
Direct Search · One-Click Import
No more juggling between websites. Search PubMed / arXiv / OpenAlex / CORE inside InkCop. Batch import to your local knowledge base — metadata auto-recovered, full-text indexed.
Advanced Query
Boolean + field filters
Select / Select All
Multi-select to target folder
Bulk Import
Metadata + full text saved
PubMed Biomedical Biomedical authority (NIH/NLM)
Standard .nbib metadata supported
arXiv STEM Physics / Math / CS preprints
Boolean query + subject filters
OpenAlex Open Access 200M+ open scholarly index
OA / fulltext filter + citation counts
CORE Aggregator World's largest OA paper aggregator
One-click full-text PDF & abstract
Bulk Local Import · Any Format
Got a massive backlog? Drag in a folder to recursively scan all supported formats. PDFs through MinerU for layout recovery; Word/EPUB/RTF/ODT via Pandoc; PNG/JPG images via OCR.
- Async background processing — keep working in the foreground
- Resume from checkpoint after app restart — no task loss
- Auto-triggers LLM preprocessing on import
- Choose target subfolder to align with your existing structure
PDF Layout preserved + AI metadata recovery
Word .doc / .docx via Pandoc
PowerPoint .ppt / .pptx slide import
EPUB E-book chapters fully parsed
Markdown Native format, zero conversion loss
RTF / ODT Rich text formats lossless import
Image PNG / JPG with OCR extraction
Plain Text Logs, notes, batch outputs
Dual Retrieval: RAG + Knowledge Graph
Vector-only retrieval drifts; graph-only retrieval is too narrow. InkCop runs both engines in parallel, cross-calibrating to give AI both "broad" and "precise" context.
RAG Vector Retrieval
Broad semantic similarity · Fault-tolerant
- ▸ObjectBox + HNSW local index, ms-level nearest-neighbor
- ▸Multimodal embeddings (text + image)
- ▸Optional reranker model for re-ranking
- ▸LLM-driven semantic chunking
Knowledge Graph Retrieval
Rigorous entity links · Multi-hop reasoning
- ▸Kuzu graph database, native Cypher queries
- ▸Multi-hop reasoning across papers
- ▸Concept nodes + entity nodes (two-tier)
- ▸Every edge carries chunk citations for verification
Dual-engine synergy: RAG retrieves candidate chunks → Graph expands by entity links → Merge & dedupe → Optional LLM relevance test → Return context. Transparent to the LLM, delivering "broad and precise" results.
LiteraturePrepareAgent · LLM-Driven Pipeline
Traditional knowledge base systems use rule-based chunking, rule-based extraction, rule-based summarization — four or five independent modules in a chain, each seeing only its slice of input. The "weakest link" drags down overall quality. InkCop reverses this: hand the entire preprocessing pipeline to a single LLM agent.
Semantic Chunking
LLM identifies semantic boundaries to chunk documents — preserving complete argument paragraphs. Avoids rule-based chunking that fragments coherent reasoning.
Entity & Relation Extraction
Identifies people, institutions, concepts, methods, metrics; extracts coreference, contrast, causality, dependency relations into the graph database.
Graph Concept Generation
Generates "concept nodes" per document for cross-paper retrieval. Powers multi-hop reasoning and orphan-concept matching — making the graph truly serve retrieval.
Summary / Keywords / Category
Single-pass production of summary, keywords, and topic classification. Combined with citation metadata, forms a complete document profile for precise retrieval.
6 Benefits of LLM-Driven Pipeline
Why not the traditional "rules + multi-module" pipeline?
Unified Context
In a traditional pipeline, each module sees only its slice of input. With LLM ownership, chunking, extraction, and summarization share the full context for deeper understanding.
Atomic Submission
All outputs commit atomically via base_data_updater / index_data_updater tools. No more “chunked OK but graph extraction failed” intermediate states.
Unified Rules, Easy Evolution
All processing logic lives in the Agent prompt. Switching research domains or upgrading rules requires only a prompt tweak — no rewriting multiple modules.
Controlled Fallback & Retry
Failed jobs persist in the signals table. App-startup scans auto-retry; manual trigger above threshold prevents silent loss.
Full LLM Capability
As LLMs improve, preprocessing quality benefits naturally. No code rewrite — just swap to a stronger model or refine the prompt.
Independent LLM Config
LiteraturePreparer can be decoupled from the chat-facing main_agent — configure a cheaper or faster local model for batch processing.
Knowledge Graph Visualization · See the Structure
The knowledge graph is not just for AI retrieval — it's your cognitive tool. AntV G6-powered interactive graph lets you literally "see" the relationship network inside your knowledge base.
Six Layout Algorithms
radial, force-cluster, concentric, antv-dagre, circular, grid — the system auto-recommends the best layout based on graph density.
Concept Graph + Document Graph
Concept graph shows cross-paper entity relations; document graph shows similarity and citation links between documents in the knowledge base. One-click switch.
Click-to-Expand Neighbors
Click any node to fetch its neighbor subgraph and merge with the current view. Progressively explore the graph without loading everything at once.
Focus Highlight + LOD
Selecting a node highlights first-degree neighbors and dims the rest. Labels auto-hide on low zoom — smooth rendering even with millions of nodes.
Related Chunks & Source Jump
A drawer shows chunks linked to the node and lets you jump straight to the source paper position. From graph to detail without tool-switching.
Keyword Search + Subgraph Filter
Filter the subgraph via the toolbar by keyword or knowledge-base ID. When nodes/edges exceed the limit, the graph auto-truncates with a notice.
Typical Use Cases
Literature Review
Find domain entity networks via the concept graph; locate research gaps; multi-hop reasoning connects implicit logic across papers.
Topic Exploration
In an unfamiliar field, start from one key concept and recursively expand neighbors — quickly build a cognitive map of the domain.
Relation Verification
Is the AI-claimed "X relates to Y" actually grounded? Every graph edge carries chunk citations for item-by-item verification.
Team Knowledge Sharing
Visualize years of team literature accumulation. New members onboard quickly without reinventing the wheel.
Complete Capability Matrix
Core capabilities for the full research lifecycle
Direct Search Across 4 Literature Platforms
Native integration with PubMed / arXiv / OpenAlex / CORE. Advanced Boolean queries with multi-dimensional filters. One-click batch import of full text + complete metadata (title, authors, journal, volume, DOI, PMID, etc.) into the local knowledge base.
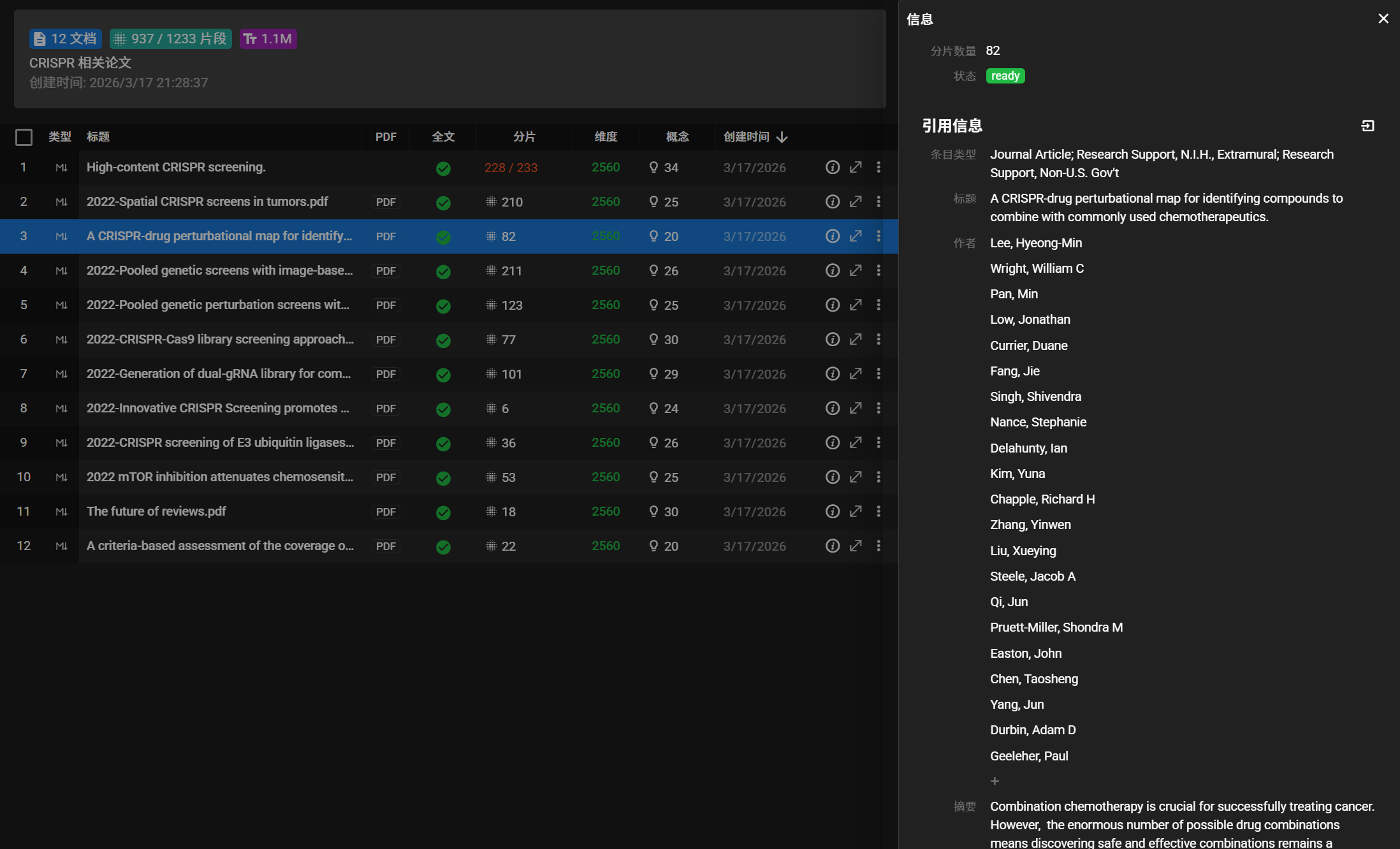
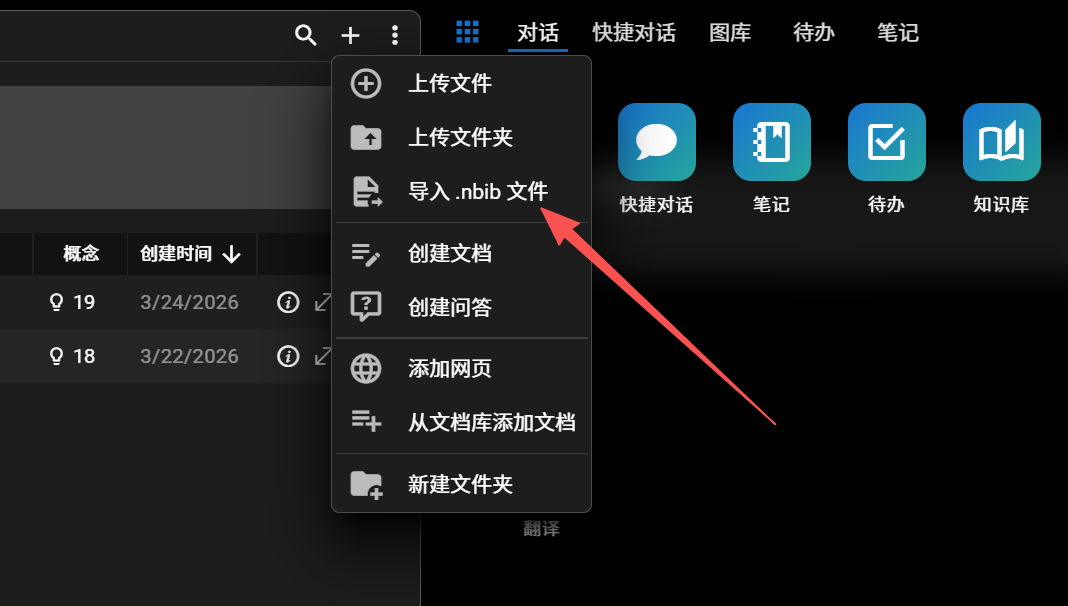
Bulk Import of Multi-Format Local Resources
Drag in a folder — recursive import. Full support for PDF / Word / PowerPoint / EPUB / RTF / ODT / Markdown / plain text plus PNG/JPG images (OCR). No more uploading one by one. Background tasks resume automatically after restart.
Dual Retrieval: RAG + Knowledge Graph
Vector RAG retrieval delivers “broad semantic similarity”; the knowledge graph delivers “rigorous entity links.” Local ObjectBox + HNSW for millisecond nearest-neighbor; Kuzu graph DB enables multi-hop reasoning across papers.

LLM-Driven Literature Preprocessing Pipeline
The LiteraturePrepareAgent owns the entire pipeline: semantic chunking, entity/relation extraction, knowledge-graph data, summary, and keywords — all in a single LLM call with atomic submission. Eliminates context loss and inconsistencies from multi-call pipelines.
Multimodal RAG & Chart Understanding
Beyond text — recognizes charts, curves, and pathology images in papers, converting them into searchable knowledge units. Supports multimodal embedding models (e.g. qwen3-vl-embedding).

Interactive Knowledge Graph Visualization
AntV G6-powered Concept Graph + Document Graph with six layouts (radial, force-cluster, concentric, Dagre, circular, grid). Click a node to expand neighbors, jump to source paper, or inspect related chunks.
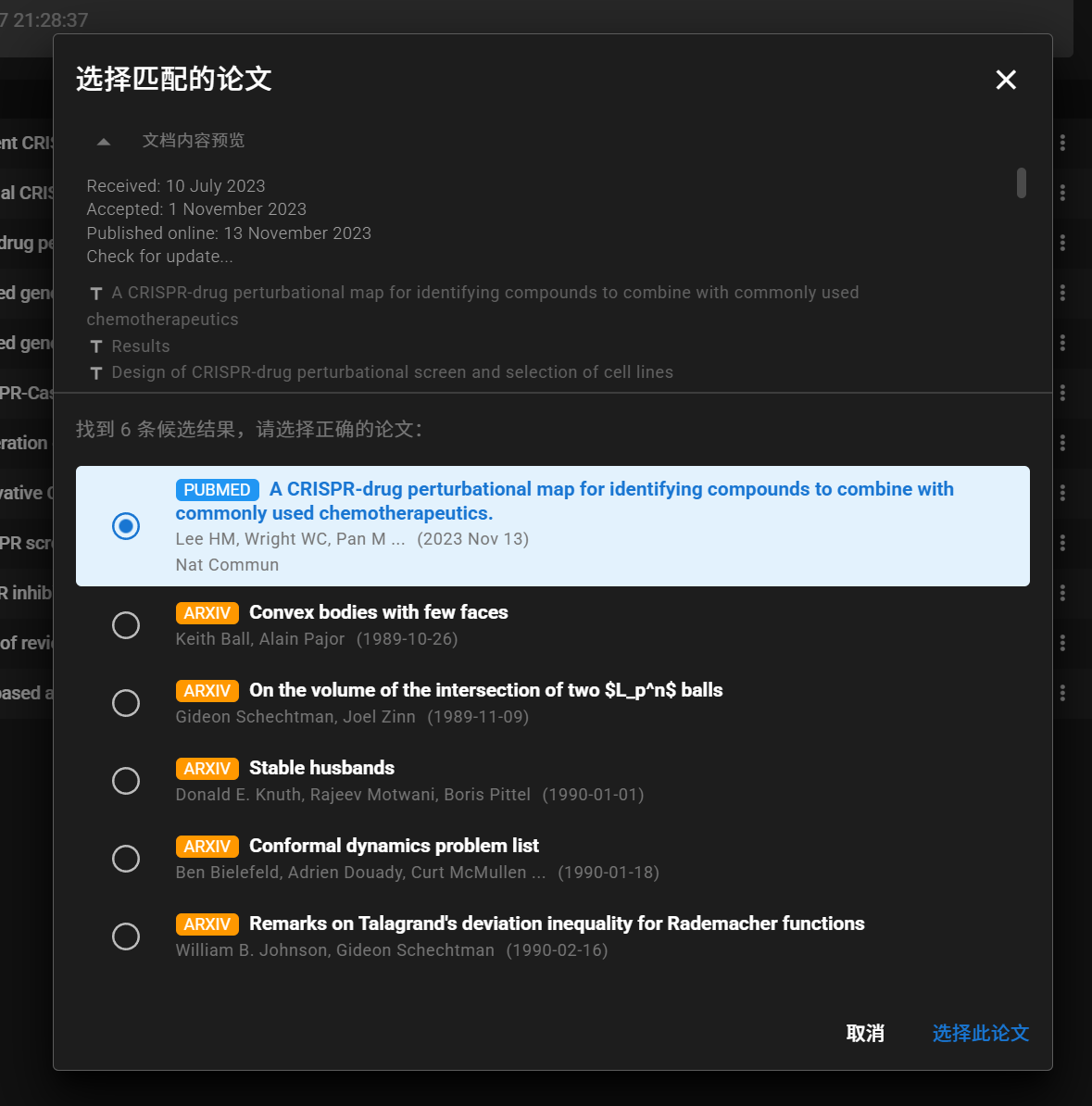
Auto Metadata Discovery & Citation Archive
Drop any PDF — AI auto-recovers title, authors, abstract, journal, DOI, PMID. Saved as Zotero-style citation in metadata. Full .nbib import support for PubMed/Endnote workflows.
Reading Guides & Visual HTML Reports
One-click reading guides, reverse reading, visual diagrams, and interactive HTML reports for every paper in the knowledge base. Grasp the core in 10 minutes.
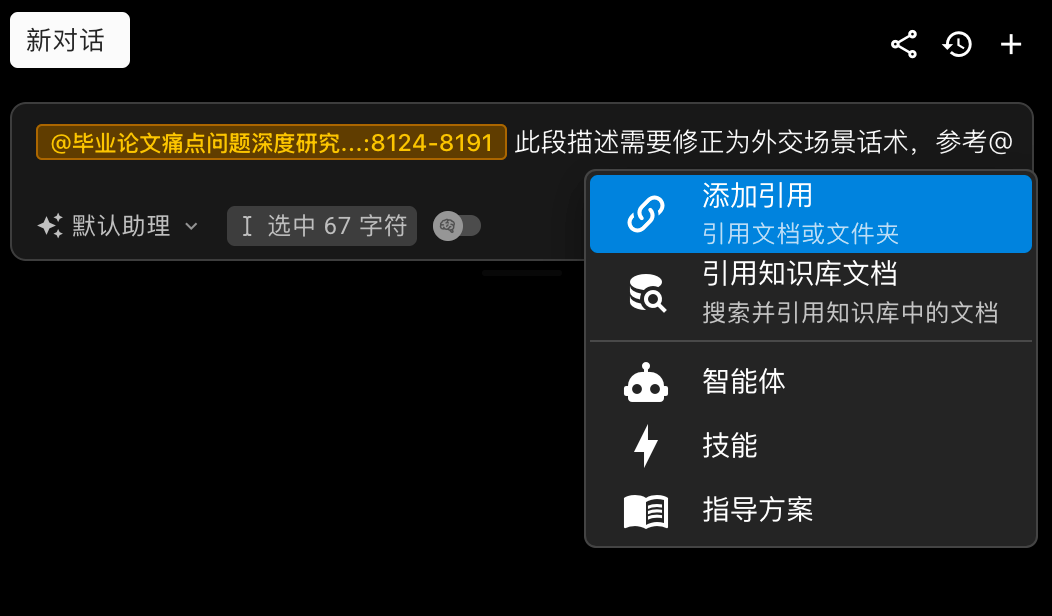
@Precise Targeting & Context Pinning
@document, @knowledge article, @specific text — pin context to objective entities for grounded answers with traceable sources.
Local knowledge base connects to all solutions: